
After showing off some early results from our NovelAI V4 model, we have decided to get it into your hands as soon as possible. We’re very excited to, hereby, announce the preview release of NovelAI Diffusion V4 — Curated Preview.
Do note that this is a preview release. That means that many features you would expect from our regular models are still missing! We are working as fast as we can to bring you the full experience, but we hope that this preview can tide you over!
Read on for more details on what exactly is and is not included with this release.
V4 is our first family of completely original image generation models, trained from the ground up without relying on a public base model like Stable Diffusion. Since the model is completely different, keep in mind that it will interpret your prompts differently from our V3 models, so you will most likely have to do some adjustments to your old prompts.
It brings many new functionalities to your toolbox, such as first class support for prompting images with multiple characters, natural language understanding and the ability to better render English text into your envisioned scenes. All that is accompanied by an enhanced level of detail, improved creativity and a vastly expanded and updated knowledge base, as well as a much expanded dataset.
Just like in the old days of V1 of our image generation models, we are releasing two different versions of the model. The first is the Curated version of the model, which we are releasing during the preview phase now, so you can get your hands on the various new features before the Holiday season. The Curated model is trained on a subset of our data, making it more suitable for use during streaming, in public, or with friends, where it is sure to dazzle with stunning images, but its knowledge is also a little more limited. The Full model, which is trained on our complete dataset and aces all the wide variety of topics our current models can handle, is currently still in training. We are sure many of you are looking forward, especially to the release of the Full model, but it needs to cook for a little longer. We are confident that the extra wait will be worth it!
Along with the Full model, which is currently still in training, the current preview release is also still missing some other important parts. Vibe Transfer is not yet available, because we need to retrain it from the ground up for the new model. The same goes for our Inpainting functionality, but this at least will simply fall back to its old V3 version, so you will still be able to inpaint your new images, just without having access to the new V4 capabilities.
Both of these features are due to be released together with the release of the Full model, which we plan to release early next year. Additionally, SMEA and SMEA Dyn samplers are not yet available, although we hope to provide them in the near future. DDIM is also unavailable. We will likely also update the Curated model itself, either along with the release of the Full model, or in the coming days.
But enough about limitations, let’s take an in-depth look at the new tools V4 offers.
New V4 Features
Let’s talk a bit more about the different, new features that V4 brings to your fingertips, as well as old features that are once again available.
Multi-Character Prompting
One of our strongest new capabilities is the fact that V4 allows you to separately specify prompts for up to six different characters in one image. Leakage of information among the characters is minimized, making it much easier to build complex scenes where multiple characters interact with each other. Especially images with original characters will benefit greatly from this new functionality.
This works by separating the prompt into a single base prompt and multiple character prompts. The base prompt determines the scene, the style of the image and so on. The character prompts allow you to describe each character in your scene in a way that keeps its prompt away from other characters, minimizing information leakage.
There are two ways of using Multi-Character Prompting. The first and recommended way is to click on the new “+ Add Character” button below the prompt box. This will add a new prompt box just for the character. Clicking into it allows you to type in that specific character’s prompt. If you find that anything does leak from somewhere else in the prompt or otherwise gets generated that you do not like, you can use the character’s Undesired Content field to prompt against it, just like for the base prompt.
When using Multi-Character Prompting, usually the model will follow the order in which you have your character prompts listed in placing them into the scene, following a top to bottom, left to right scheme. For example, if you have two characters and the “side-by-side” tag, the character in your first prompt box will usually appear on the left, while the one in the second will appear on the right side of your image. The up and down arrows at the upper right of each character prompt box lets you quickly change the order of your characters.
Additionally, there is a way to (very roughly) indicate where in the image you want your characters to appear. This is a bit of an advanced feature and more of a nudge or a light suggestion to the model, so it is best if the positions you set do not conflict with the order of your character prompt boxes and are also reinforced with natural language prompting. To make use of this feature, you need to have at least two character prompt boxes set up. Disable the “AI’s Choice” toggle below your character prompt boxes. Now, when you click on a character prompt box, you will be able to click on the “Position” button, which will open another UI, where you are presented with a 5x5 grid. Click on any cell in this grid and confirm it with “Done” to set the rough position of your character.
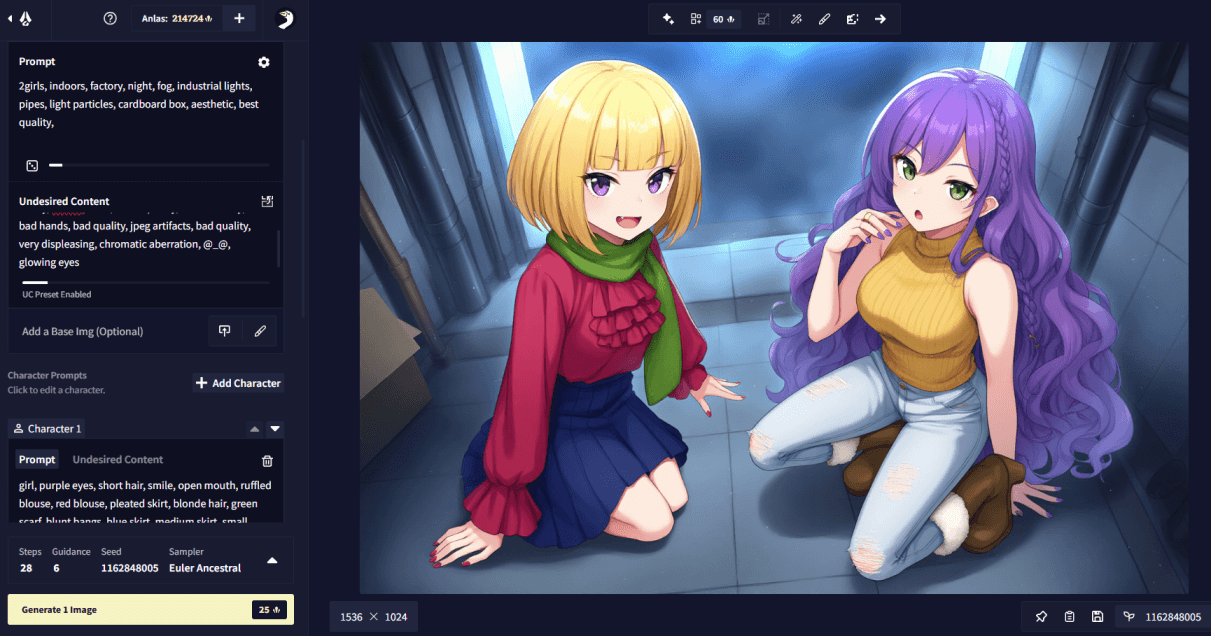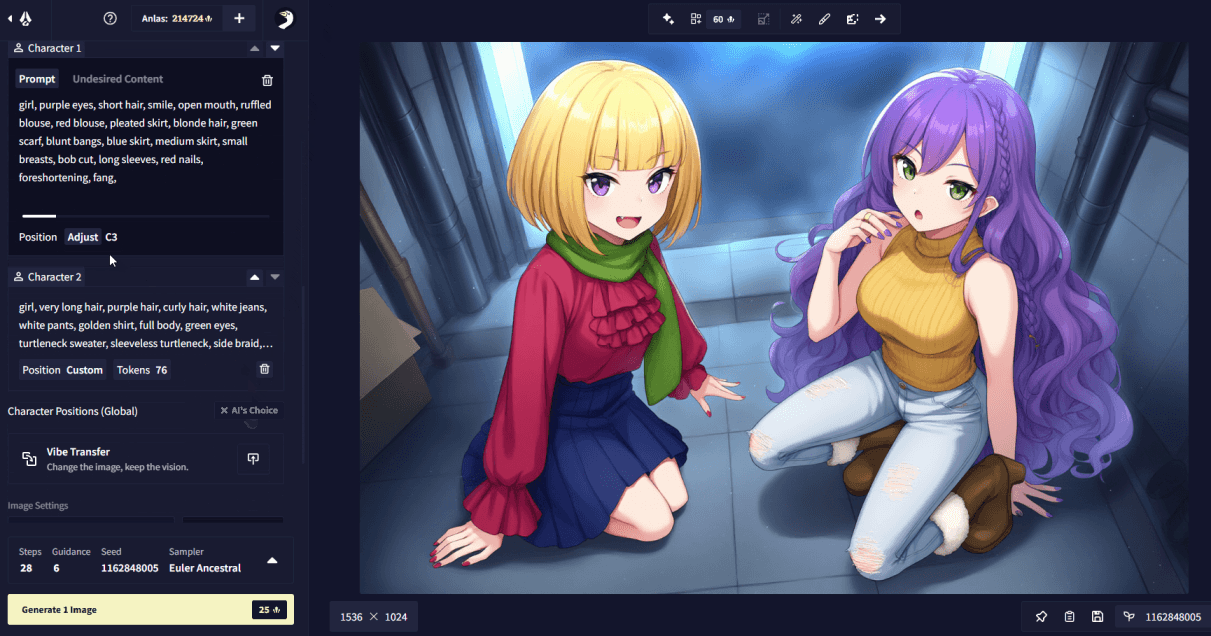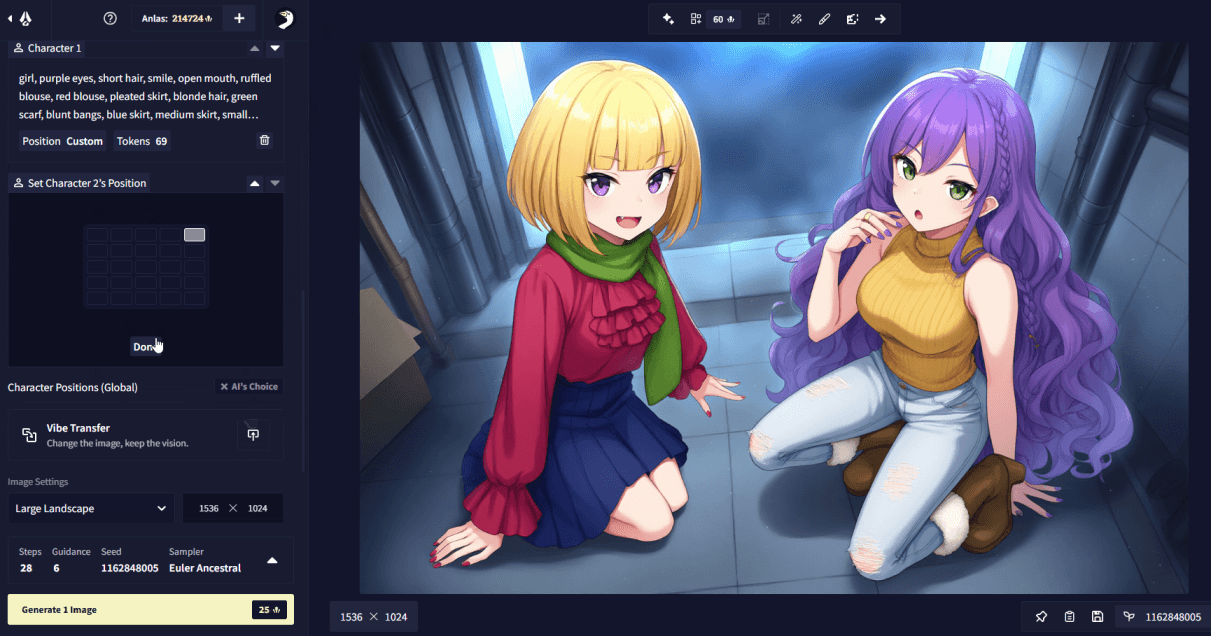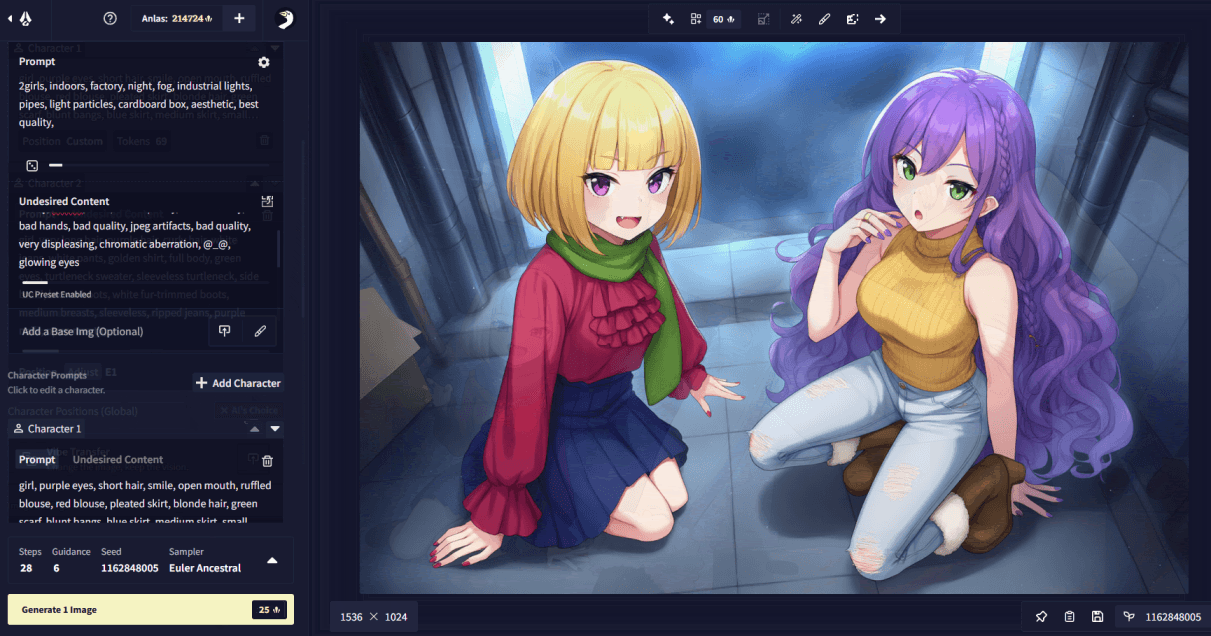
Another thing that should be noted is regarding the character count tags (i.e. Xboys, Ygirls, Zothers). These tags should always go into the base prompt part (e.g. “2girls, 2boys, outdoors, …”), then in each character prompt, just “girl”, “boy”, or “other” is specified, without a count, to let the model know how to draw the character (e.g. “girl, purple hair, …” or “boy, blonde hair, …”) described in the given character slot.
If you are just quickly trying something out and clicking buttons seems too bothersome, you can also use the | character in your prompt to separate the base prompt and character prompts. Prompt mixing is not available on V4, so the | character is used for this purpose instead. Note that it is NOT possible to mix the | prompt syntax with the character prompt boxes. If any character prompt box exists, the | syntax is disabled. An example prompt using this syntax could be:
2girls, indoors, factory, night, fog, industrial lights, pipes, light particles, cardboard box, aesthetic, best quality, english text, text | girl, purple eyes, short hair, smile, open mouth, ruffled blouse, red blouse, pleated skirt, blonde hair, green scarf, hands on own hips, blunt bangs, blue skirt, medium skirt, small breasts, bob cut, target#pointing, long sleeves, red nails, fang, cowboy shot. She is being pointed at. | girl, very long hair, purple hair, curly hair, white jeans, white pants, golden shirt, cowboy shot, green eyes, turtleneck sweater, sleeveless turtleneck, side braid, medium breasts, sleeveless, ripped jeans, wavy mouth, blush, purple nails, open mouth, source#pointing at another, speech bubble. She is pointing at the other girl and scolding her. Text: Stop that!
Action Tags
We have added a new, special syntax to more clearly specify action tags in character prompts. When multiple characters interact, the action tag syntax allows you to specify who the active and passive parties are by prefixing an action tag like “hug” with either “source#”, “target#” or “mutual#”. For example, if one character is hugging another, on that character you could specify the source#hug tag. On the character that is being hugged, you would then specify the target#hug tag. If the characters are hugging each other, you can, on both sides, use the mutual#hug tag.
Note that this syntax is not always reliable, but it can be helpful in many cases.
Natural Language Understanding
In many cases, it can be difficult to express something with tags alone. Our new V4 models are able to understand natural language descriptions, making it much easier to prompt for specific results you want to achieve. If you do not know a tag for something, you can try describing it in natural language.
Example:
1girl, sundress, looking at viewer, full body. There are three objects. A single red cube. A single blue cube is placed on top of the red cube. A single green sphere lies to the left of the red cube, just next to it. The girl is standing to the right, next to the red cube. Digital illustration. Highly finished. Still life. Character Study.
One important thing to note is that the model is now case sensitive and whitespace sensitive. It is strongly recommended that you never use underbars (_) inside your tags (except in the case of smileys like “^_^”), write all your tags in lower case and separate them with a comma followed by a space (“, “). Natural language descriptions should be written following the rules of English grammar, spelling, and capitalization.
Longer Prompts
There is now a higher prompt token length limit of up to ~512 T5 tokens over the base prompt and all character prompts combined, giving you more space to express your ideas than ever before.
One thing to note is that since the T5 tokenizer is used, be aware that most Unicode characters (e.g. colorful emoji or Japanese characters) are not supported by the model as part of prompts.
16 Channel VAE
This perhaps sounds a bit technical, but our past models all used 4 channel Variational Auto Encoders (VAE). The purpose of a VAE is translating images from RGB pixels into the “language” of the model and back. The number of channels basically determines how fine the details are that the model can see, learn from and then draw. By upgrading to a 16 channel VAE, we are giving the model a boost in the fine detail department, from which many things like eye details, jewelry, and text will benefit. Specifically, our model uses the Apache 2.0 licensed 16 channel FLUX VAE.
Text
While V4 is not going to put novels full of text into your image, it is definitely more capable of writing legible English text than our V3 models are. The best way to prompt for text is to include the text, english text tags in your prompt and end it on a period followed by “Text:” and whatever text you want to show up in your image.
If the model struggles with spelling, writing your text in all uppercase can sometimes help. If you want the text in a specific location, you can use natural language to describe where the text should appear, unless your tags otherwise make it obvious (e.g. speech bubble). If you want your characters to say something, you can also try putting “Text:” in the character prompt boxes rather than the base prompt one. As a final bit of advice, it can help to repeat things for the model. Putting it all together, here is an example:
1girl, text, english text, speech bubble, white background. A pastel pink speech bubble with yellow handwritten text says “HAVE FUN!”. Text: HAVE FUN!
Quality and Year Tags
As in our past models, you can use our aesthetics, quality and year tags.
- Quality tags: best quality, amazing quality, great quality, normal quality, bad quality, worst quality
- Aesthetics tags: very aesthetic, aesthetic, displeasing, very displeasing
- Year tags: year 2024 or any other year will change the style of your image to match more closely the prevalent style of images drawn in the indicated year.
Image2Image
A staple functionality of our image generation models. This functionality is, of course, available, even in this limited Preview release.
New Special Tags and Phrases
We have also added some additional, new tags that may produce interesting effects. This is not a comprehensive list, but should be enough to get you started!
- Character Study can be used to place more focus on the characters in the scene. If your image is very zoomed out, adding this can help. Additionally, a phrase like “the characters are the central focus of this image” can further be helpful.
- Special tag combinations and tags:
- photo (medium), photographic doll, fumo (doll) will generate a plushy in the fumo style.
- photo (medium), figure will generate characters in the form of a plastic figure.
- artist:ainiwaffles will generate images in the style of Aini, which will be a familiar look to everyone who knows the character personifications of our text generation models.

Natural language can also influence the art style of your image. You can try the following turns of phrase in a natural language sentence and tweak things to your liking by adjusting the wording:
- highly finished indicates that the image is not unfinished in any way, linework is clean, shading is fully complete.
- Digital illustration can overall increase the quality of your generation in some cases and push towards a less realistic style.
- Anime style can specifically push towards more anime-like styles, which can be useful in some cases.
- smooth shading indicates a style of shading that is smooth and less “cel shading”-like.
- smooth, shiny shading additionally emphasises shiny highlights.
- Try combining things together in a sentence like: The image is a highly finished digital illustration in anime style with smooth, shiny shading.
Image Showcase
Check out these incredible creations below! Our amazing community of testers and our very own Anlatan devs have been putting NovelAI V4 Curated Preview through its paces — and the results speak for themselves! We’re blown away by the creativity!
















































That is all!
We hope that you will enjoy generating amazing images with the V4 preview release just as much as we do and look forward to seeing your amazing creations.
Please feel free to share them on social media like X in the #NovelAI or #NAIV4 hashtags.
